
Episode 2: Mapping the Field
What a transparent literature search with Claude revealed about late-onset sepsis prediction in preterm infants — and what it means for CEPAS 2026.


I’m senior author on one of the more recent ML papers for late-onset sepsis prediction in preterm infants. I collaborate with several of the others doing this work. I thought I knew the field, kept up with literature.
In Episode 1 I traced the lineage from HeRO and the Moorman trial through to the present. The question I’m building toward for CEPAS 2026 is harder: where does the field actually stand right now? Not where the headlines say it is. Where the literature actually says it is.
What follows is the result of a staged literature search with Claude. Five search rounds, roughly 200 abstracts triaged, full text on seven anchor papers, two systematic reviews. The chat log is the source material; this post is what came out the other end.
First surprise: the field has its own dialect
I started where any clinician would. PubMed, “neonatal sepsis” AND “machine learning”, filtered for the last 15 years. 101 papers. The top of the list looked sensible, Kainth’s 2024 systematic review, a handful of clinical-features models, the usual review pieces.
Then I narrowed to “late-onset sepsis” AND “preterm” AND ML. Forty papers. Four obvious anchors: Berg, Kausch, Yang, Meeus. I thought I had the field.
Three more searches to be sure and the actual count was at least seven academic groups, plus a second systematic review I hadn’t seen.
The problem was in the vocabulary. My searches were in machine learning terminology — “machine learning”, “prediction model”, “algorithm”. But a substantial part of the field uses physiology terminology — “heart rate characteristics”, “HRC index”, “HRV”, “visibility graph”. Those papers don’t reliably surface on ML keyword searches, even though they’re doing the same job for the same patients.
The clearest evidence was the discovery of two separate systematic reviews of the same clinical problem, written within months of each other, with almost no overlap in cited literature:
Kainth et al. 2024 (Pediatr Infect Dis J): 19 studies, pooled AUC 0.94. Reviews ML models using clinical and laboratory features. Explicitly excludes vital-signs-only studies.
Koppens et al. 2023 (Neonatology, Amsterdam UMC): 15 studies, 8,230 infants. Reviews HRC monitoring for LOS in preterm. This is the vital-signs branch.
The two reviews do not cite each other. They are reviewing the same clinical problem, early detection of LOS in preterm infants, through two different methodological lenses, and the camps don’t talk. Calling them Branch A (continuous vital signs) and Branch B (snapshot clinical and lab features) is the best way to keep them straight. Our paper is Branch A.
Searching the right field requires speaking its dialect. That was the first lesson, and one I wish I’d known when I started Episode 1.
The complete map
After five staged searches and a careful read of both systematic reviews, the active groups in Branch A, continuous-physiology ML for LOS in preterm infants, are:
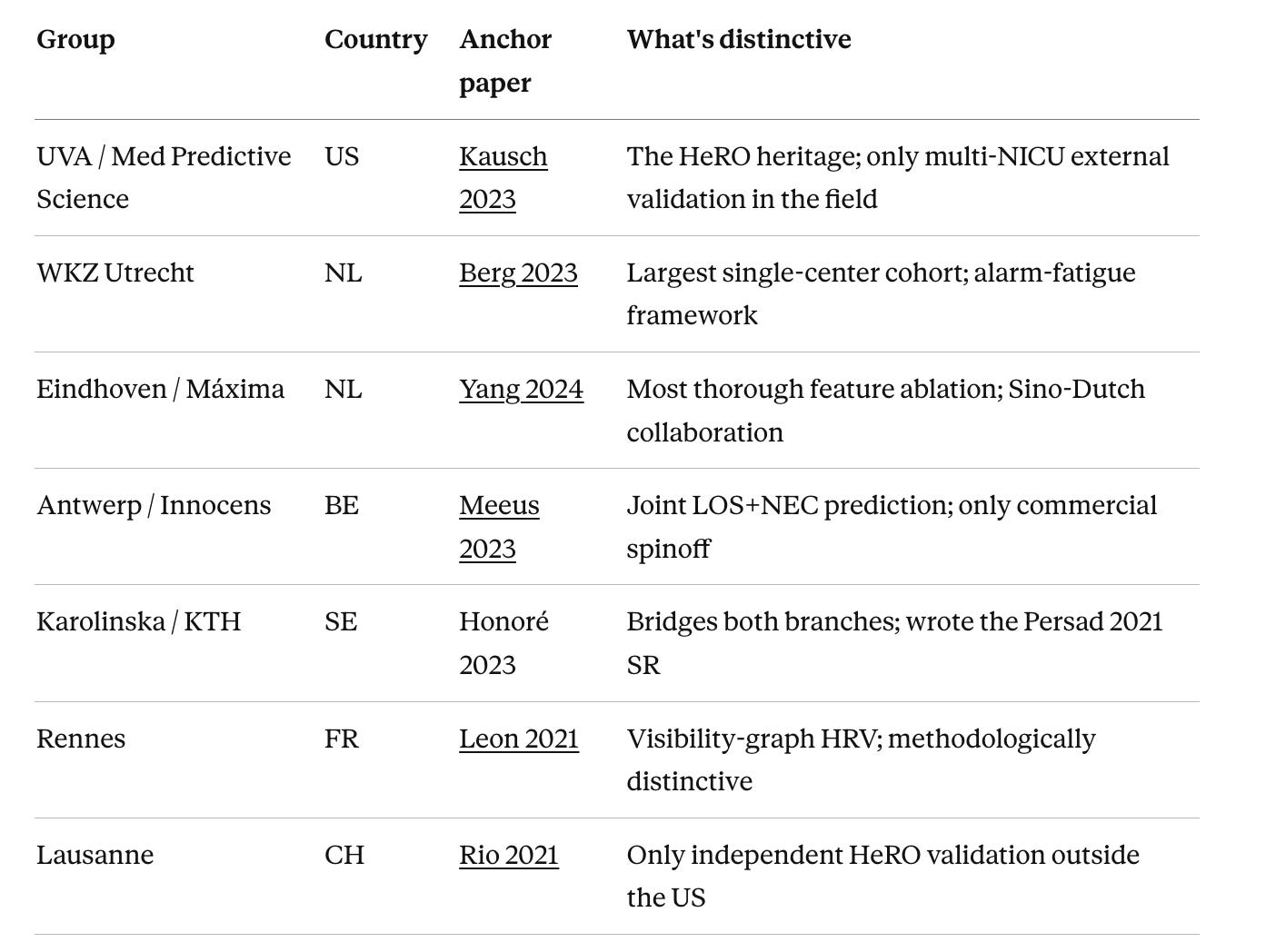
UVA / Med Predictive Science (US) — Kausch SL et al. 2023, Pediatric Research. DOI: 10.1038/s41390-022-02444-7. The HeRO heritage; only multi-NICU external validation in the field.
WKZ Utrecht (NL) — van den Berg M et al. 2023, Computers in Biology and Medicine. DOI: 10.1016/j.compbiomed.2023.107156. Largest single-center cohort; alarm-fatigue framework.
Eindhoven / Máxima (NL) — Yang M et al. 2024, Computer Methods and Programs in Biomedicine. DOI: 10.1016/j.cmpb.2024.108335. Most thorough feature ablation; Sino-Dutch collaboration.
Antwerp / Innocens (BE) — Meeus M et al. 2024, Journal of Pediatrics. DOI: 10.1016/j.jpeds.2023.113869. Joint LOS+NEC prediction; only commercial spinoff.
Karolinska / KTH (SE) — Honoré A et al. 2023, Acta Paediatrica. DOI: 10.1111/apa.16660. Bridges both branches; senior co-authors wrote the Persad 2021 SR.
Rennes (FR) — Leon C et al. 2021, IEEE Journal of Biomedical and Health Informatics. DOI: 10.1109/JBHI.2020.3021662. Visibility-graph HRV; methodologically distinctive.
Lausanne (CH) — Rio L et al. 2022, Pediatric Research. DOI: 10.1038/s41390-021-01913-9. Only independent HeRO validation outside the US.
Two synthesis papers anchor the field: Koppens 2023 (Branch A) and Kainth 2024 (Branch B).
A few observations on this map.
Geography. Four of the seven groups are in continental Western Europe, two Dutch centres, plus Belgium, France, Switzerland, and one is in Sweden if you count the Karolinska bridge group. One is in the US. Couldn’t find any in Asia, Africa, or Latin America. I checked specifically for Chinese Branch A work, because the Chinese neonatology literature is data-rich and methodologically capable. The Chinese research bet in this space is firmly on Branch B, lab-feature and clinical-variable nomograms. The continuous-physiology ML problem is, almost entirely, a Western European and American research phenomenon.
Time. The field has gone a bit quiet in 2024–2026. I checked the 184 most recent papers after the Kainth SR cutoff. Almost none are new Branch A LOS prediction work from the major groups. The work has broadened, to NEC, to catheter-related bloodstream infections, to LMIC adaptation, to regulatory questions, but it has not deepened. There has been no major new model paper from any of the seven groups in roughly 18 months.
What every group is finding
This is the part I expected to be messy. It turned out to be cleaner than I thought.
Across all seven anchor papers, different signal stacks (1-channel to 7-channel), different sampling rates (1/h to 250 Hz), different ML methods (logistic regression to deep learning), different cohort sizes (51 to 3,151), AUCs converge on 0.78–0.88 at the moment of clinical suspicion. The single external validation in the field (Kausch trained on UVA, tested on Columbia and St Louis) drops AUC by about 0.03 across centres. The convergence is real, and it isn’t a methodological artifact.
The more clinically meaningful number is what fraction of LOS episodes are detected before clinical recognition:
Berg 2023: 47–60% of patients detected pre-clinically, using a multi-threshold alarm policy.
Kausch 2023: significant risk elevation 23–24 hours before blood culture.
Yang 2024: 96% patient-wise detection before clinical suspicion, but on a small cohort (n=119).
Meeus 2023: 69% of all episodes, 81% of severe episodes; median time gain 10 hours.
The consensus is this: roughly half to two-thirds of LOS episodes appear to be detectable hours before clinical recognition with current technology. That is the technical answer to the central question of the field.
Two methodological points that matter more than they get credit for:
Yang’s sampling-rate ablation is the most underrated paper in this list. They compared raw waveforms (AUC 0.886) → 1 Hz vitals (0.875) → 1/min vitals (0.825) → 1/h vitals (0.687). The 1/min-to-1/h jump destroys the signal. The 1 Hz-to-1/min jump costs about 5 AUC points. What this tells you is that minute-by-minute data works fine; once you summarize to hourly aggregates, the signal collapses. That’s the floor of deployable signal resolution, and it’s empirically settled now.
Kausch’s pulse-rate-equals-ECG finding is the most underrated result. They showed that POWS performance was within 0.01 AUC whether the heart-rate signal came from ECG or from pulse oximetry. That means a Branch A model can run on a standalone pulse oximeter, no ECG leads, no specialized monitor. For low-resource deployment, that is the difference between a research curiosity and a deployable tool.
What every group is choosing not to do
A consistent finding across the papers that compared multiple ML methods: none of them found that complex models beat simple ones. Berg compared logistic regression, GAMs, and XGBoost, all within 0.01 AUC, chose LR for interpretability. Kausch compared LR with cubic splines, neural networks, XGBoost, and random forest, all within 0.01 AUC, chose LR (”equal performance, better explainability”). Yang compared seven methods including two deep-learning architectures, gradient boosting won; deep learning actually underperformed on their cohort.
This is unusual for an ML field in 2024–2026. It means LOS prediction is not a deep-learning-shaped problem (yet?). It is a feature-engineering problem with a clear physiological signal stack, and once you have the right features, linear and tree-based methods reach the same ceiling. The interesting work is in choosing features, not architectures.
Said differently: the bottleneck in this field is not algorithm sophistication. It’s the things ML alone can’t fix.
Where I think the WKZ contributed
I’ll claim one specific thing for our group, because reading the comparative literature makes it visible in a way it wasn’t when we published.
The Berg 2023 paper proposed a specific framework for evaluating these models the way a clinician would actually experience them: continuous hourly prediction, multi-threshold alarms with an 8-hour refractory period (the length of a NICU shift), and explicit accounting for false-alarm burden as alarms per patient-day. The point was to stop optimizing for AUC alone and start optimizing for what bedside clinicians would tolerate.
Within 12 months, two other groups had adopted the same framework. Yang 2024 cites Berg explicitly as the basis for their multi-threshold alarm policy. Meeus 2023 echoes the alarm-rate accounting. The 8-hour shift-length refractory period and the threshold-escalation rule are now a small but real convention in this corner of the field.
I’m not claiming we solved LOS prediction. The actual modelling work is roughly equivalent across the major groups. What I’ll claim is that WKZ set a convention for how to evaluate these models for deployment, and the field adopted it. That’s worth saying.
The honest gap: the deployment vacuum
Here is what is not in the literature, despite 15 years of work and seven productive academic groups:
Zero prospective validation studies of any of these models in current clinical use.
One randomized controlled trial. The Moorman 2011 HeRO trial. Fourteen years old. Mortality benefit ARR 2.07%, NNTM 49 (95% CI 24–15,484). High risk of bias per the Cochrane assessment. The long-term follow-up (King 2021) showed persistent mortality reduction at 18–22 months, but also an unexplained increase in deafness in the HRC-monitored arm (4.4% vs 0.5%), possibly aminoglycoside-related.
One independent external validation of the only commercial product. Rio 2021, single-centre Lausanne data, showed real-world HeRO performance is strongly gestational-age-dependent: sensitivity 76% in infants below 28 weeks, falling to 25% above 32 weeks. The optimal threshold in their cohort was 2.76, not the FDA-cleared 2.0.
One commercial deployment outside HeRO: Innocens BV, the Antwerp spinoff. Currently navigating the European MDR/CE certification pathway. Vrijlandt et al. 2026 (Erasmus MC) is the first published paper to think through what that regulatory pathway looks like for paediatric clinical decision support in Europe.
The Koppens 2023 SR lands the policy verdict most directly: “methodological weaknesses and limited generalizability do not justify implementation of HRC in clinical care. A large international RCT is warranted.”
That is the gap. We have seven academic groups, four major model papers, two systematic reviews, one underpowered 2011 RCT, one independent external validation showing real-world drift, and one commercial product navigating European regulation. The technical question “can we predict LOS pre-clinically with ML?” has been answered, “reasonably well”. The deployment question is wide open.
What this means for CEPAS
I came into this search expecting to summarize the technical state of the art. I’m leaving it convinced that’s the wrong talk to give.
The technical state of the art is converged. AUCs at 0.78–0.88. Half to two-thirds of LOS episodes detectable hours before clinical recognition. Feature engineering, not architecture, drives the ceiling. Pulse-rate-only signal stacks work. Alarm-fatigue frameworks are now field convention.
What is missing is everything that turns a model into a deployable clinical tool: prospective trials, international validation, regulatory clarity, deployment infrastructure outside high-income academic centres, and an honest accounting of what real-world performance looks like once you leave your training cohort.
Episode 3 will go deeper on the head-to-head between the major model papers, specifically on signal stack choices and alarm policy design, because those decisions matter more than the ML methodology and almost nobody writes about them clearly. After that, the series turns toward deployment and the European regulatory frame.
If you spotted a group I missed in the map, or have a paper I should have anchored on, please tell me. The whole point of doing this transparently is to fix what I get wrong.
This post is part of “Road to CEPAS 2026”, a transparent research diary as I prepare a 20-minute talk for the CEPAS 2026 congress in Lyon. Episode 1 traced the HeRO/Moorman lineage; this episode maps the current state of the field. The full chat transcript that produced this post will be available on neonatology.ai.